PALSAR-2のSAR画像を取得する
はじめに
PALSAR-2はALOS-2に搭載された、マイクロ波を地表面に照射し、地表面から反射される電波を受信することで情報を取得する、合成開口レーダ(SAR)と呼ばれるセンサです。得られるSARデータの解像度は3~100mとなります。APIを利用して、PALSAR-2のシーン画像を取得してみましょう。
シーンを取得する
PALSAR-2のシーンデータを取得するためには、ほかのデータセットのシーンデータと区別するため、カタログ情報として記載されている、観測バンド(SAR)、処理レベル、解像度等を入力する必要があります。
まずは、シーンデータを取得するための関数を定義しましょう。
import json
import pprint
import numpy as np
import requests
from skimage import io
from tifffile import TiffFile
TOKEN = "ここに自分のトークンを貼り付ける"
# PALSAR-2のシーン情報を取得
def scene_search_crossing(
datasets=None, intersects=None, query={}, sortby=None, paginate=None
):
url = "https://www.tellusxdp.com/api/traveler/v1/data-search/"
headers = {"Authorization": "Bearer " + TOKEN, "content-type": "application/json"}
payloads = {}
if isinstance(datasets, list):
payloads["datasets"] = datasets
if intersects is not None:
payloads["intersects"] = intersects
if query is not None:
payloads["query"] = query
if isinstance(sortby, list):
payloads["sortby"] = sortby
if paginate is not None:
payloads["paginate"] = paginate
r = requests.post(url, headers=headers, data=json.dumps(payloads))
return r.json()
関数を実行して関東周辺のデータを取得します。AOIの座標指定時には、反時計周りで1つ目と5つ目の座標は同じ値を設定してください。
# 関東周辺
# プロパティ指定条件:観測バンド(SAR)=L、処理レベル=L2.1、解像度=3m
pprint.pprint(
scene_search_crossing(
intersects={
"type": "Polygon",
"coordinates": [
[
[139.967, 35.771],
[140.573, 35.682],
[140.71, 36.293],
[140.099, 36.382],
[139.967, 35.771],
]
],
},
query={
"sar:frequency_band": {"eq": "L"},
"processing:level": {"eq": "L2.1"},
"gsd": {"eq": 3},
"sar:polarizations": {"eq": "HH"},
"sar:instrument_mode": {"eq": "UBS"},
},
sortby=[{"field": "properties.end_datetime", "direction": "desc"}],
paginate={"size": 10, "cursor": None},
)
)
続いて、以下のようにファイル一覧情報取得API、個別ファイル情報取得API 、ダウンロードURL取得APIを定義します。
# ファイル一覧情報取得API
def get_files_list(dataset_id, data_id):
url = "https://www.tellusxdp.com/api/traveler/v1/datasets/{}/data/{}/files/".format(
dataset_id, data_id
)
headers = {"Authorization": "Bearer " + TOKEN, "content-type": "application/json"}
r = requests.get(url, headers=headers)
return r.json()
# ファイル情報取得API
def get_file_info(dataset_id, data_id, file_id):
url = "https://www.tellusxdp.com/api/traveler/v1/datasets/{}/data/{}/files/{}/".format(
dataset_id, data_id, file_id
)
headers = {"Authorization": "Bearer " + TOKEN, "content-type": "application/json"}
r = requests.get(url, headers=headers)
return r.json()
# ダウンロードURL取得API
def get_download_url(dataset_id, data_id, file_id):
url = "https://www.tellusxdp.com/api/traveler/v1/datasets/{}/data/{}/files/{}/download-url/".format(
dataset_id, data_id, file_id
)
headers = {"Authorization": "Bearer " + TOKEN, "Content-Type": "application/json"}
r = requests.post(url, headers=headers)
return r.json()
検索結果の中から以下のデータを用いて、ファイルのダウンロード、画像の表示を行います。
# ダウンロードしたいファイル情報を定義
dataset_id = "b0e16dea-6544-4422-926f-ad3ec9a3fcbd"
data_id = "2d27d452-aa19-47c8-9b4e-69f83571afda"
print(get_files_list(dataset_id, data_id))
データに含まれるファイル一覧の出力結果が以下のようになります。

確認したファイルIDを用いて、ファイルのダウンロードを行います。ファイルはCOG形式のものを選択しています。
file_id = "4" # tifファイルを選択
# APIを実行
file_info = get_file_info(dataset_id, data_id, file_id)
file_name = file_info["name"]
download_url = get_download_url(dataset_id, data_id, file_id)
file_info = get_file_info(dataset_id, data_id, file_id)
# 取得した情報から必要な情報を取り出す
url = download_url["download_url"]
file_name = file_info["name"]
size_bytes = file_info["size_bytes"]
print("ファイル名:" + file_name)
print("ファイルサイズ:" + str(size_bytes))
# 取得したファイルの内容を書き出す
response = requests.get(url)
with open(file_name, "wb") as f:
for chunk in response.iter_content(chunk_size=1024):
if chunk:
f.write(chunk)
f.flush()
# 取得した画像を表示する
io.imshow(file_name)
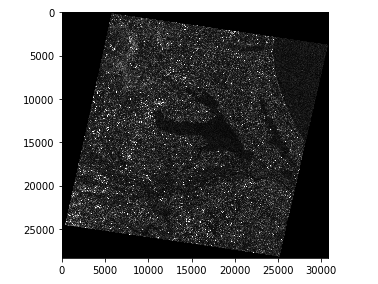
霞ヶ浦周辺のSAR画像が取得できました。このままの状態だと表示範囲が広いため、画像の一部分を切り出して拡大表示します。
# 画像をメモリマップとして返す
with TiffFile(file_name) as tif:
mmap = tif.asarray(out="memmap")
print(mmap.shape)
# 領域を切り出す
img = np.asarray(mmap[16000:20000, 18000:24000])
io.imshow(img)

霞ヶ浦と、川、川に沿った農地らしきものが見えてきました。上の画像のようにSARはモノクロの画像であり、光学画像のように対象物が何であるのかが明確ではありません。SARを用いて何ができるのかについては、マイクロ波基礎に詳しい説明があります。ご参考ください。
今回使用したスクリプトです。
import json
import pprint
import requests
from skimage import io, transform, util
TOKEN = "ここに自分のトークンを貼り付ける"
# SLATSのシーン情報を取得
def scene_search_crossing(
datasets=None, intersects=None, query={}, sortby=None, paginate=None
):
url = "https://www.tellusxdp.com/api/traveler/v1/data-search/"
headers = {"Authorization": "Bearer " + TOKEN, "content-type": "application/json"}
payloads = {}
if isinstance(datasets, list):
payloads["datasets"] = datasets
if intersects is not None:
payloads["intersects"] = intersects
if query is not None:
payloads["query"] = query
if isinstance(sortby, list):
payloads["sortby"] = sortby
if paginate is not None:
payloads["paginate"] = paginate
r = requests.post(url, headers=headers, data=json.dumps(payloads))
return r.json()
# ファイル一覧情報取得API
def get_files_list(dataset_id, data_id):
url = "https://www.tellusxdp.com/api/traveler/v1/datasets/{}/data/{}/files/".format(
dataset_id, data_id
)
headers = {"Authorization": "Bearer " + TOKEN, "content-type": "application/json"}
r = requests.get(url, headers=headers)
return r.json()
# ファイル情報取得API
def get_file_info(dataset_id, data_id, file_id):
url = "https://www.tellusxdp.com/api/traveler/v1/datasets/{}/data/{}/files/{}/".format(
dataset_id, data_id, file_id
)
headers = {"Authorization": "Bearer " + TOKEN, "content-type": "application/json"}
r = requests.get(url, headers=headers)
return r.json()
# ダウンロードURL取得API
def get_download_url(dataset_id, data_id, file_id):
url = "https://www.tellusxdp.com/api/traveler/v1/datasets/{}/data/{}/files/{}/download-url/".format(
dataset_id, data_id, file_id
)
headers = {"Authorization": "Bearer " + TOKEN, "Content-Type": "application/json"}
r = requests.post(url, headers=headers)
return r.json()
# ダウンロードしたいファイル情報を定義
dataset_id = "3ba0d35d-95c6-429d-af8b-f8d09ad318b3"
data_id = "9972ccc1-0dec-4cf8-a951-02fcd2267906"
print(get_files_list(dataset_id, data_id))
file_id = "1" # tifファイルを選択
# APIを実行
file_info = get_file_info(dataset_id, data_id, file_id)
download_url = get_download_url(dataset_id, data_id, file_id)
# 取得した情報から必要な情報を取り出す
url = download_url["download_url"]
file_name = file_info["name"]
size_bytes = file_info["size_bytes"]
print("ファイル名:" + file_name)
print("ファイルサイズ:" + str(size_bytes))
# 取得したファイルの内容を書き出す
response = requests.get(url)
with open(file_name, "wb") as f:
for chunk in response.iter_content(chunk_size=1024):
if chunk:
f.write(chunk)
f.flush()
# 取得した画像を表示する
io.imshow(file_name)
# ファイルの画像サイズ
img = io.imread(file_name)
print(img.shape)
img = transform.resize(img, (img.shape[0] * 2, img.shape[1] * 2, 3), anti_aliasing=True)
row_split = 40
col_split = 60
# 画像を切り抜き
row1_size = img.shape[0] // row_split
col1_size = img.shape[1] // col_split
img_tri = img[: (row1_size * row_split), : (col1_size * col_split), :]
Ims = util.view_as_blocks(img_tri, (row1_size, col1_size, 3))
# 切り出した範囲を指定して画像を表示する
io.imshow(img[row1_size * 20 : row1_size * 30, col1_size * 15 : col1_size * 25, :])