SLATS(つばめ)の衛星画像を取得する
はじめに
SLATS(超低高度衛星技術試験機「つばめ」)は小型高分解能光学センサ(SHIROP)を搭載し、高度300㎞以下の超低高度軌道からの観測によって地上分解能を向上することができることを技術実証するために打ち上げられました。
「SLATS(つばめ)」はJAXAの技術試験衛星で、解像度1m以下の高解像度モノクロ画像をTellusで見ることができます。この衛星の最大の特徴は、2019年の4月からおよそ1ヶ月間、ほぼ毎日東京の決まった地点を観測し続けたことです。
シーンデータを取得する
SLATSのシーンデータを取得するためには、ほかのデータセットのシーンデータと区別するため、カタログ情報として記載されている、観測バンド(OPS)、処理レベル、解像度を入力する必要があります。
まずは、シーンデータを取得するための関数を定義しましょう。
import json
import pprint
import requests
from skimage import io, transform, util
TOKEN = "ここに自分のトークンを貼り付ける"
# SLATSのシーン情報を取得
def scene_search_crossing(
datasets=None, intersects=None, query={}, sortby=None, paginate=None
):
url = "https://www.tellusxdp.com/api/traveler/v1/data-search/"
headers = {"Authorization": "Bearer " + TOKEN, "content-type": "application/json"}
payloads = {}
if isinstance(datasets, list):
payloads["datasets"] = datasets
if intersects is not None:
payloads["intersects"] = intersects
if query is not None:
payloads["query"] = query
if isinstance(sortby, list):
payloads["sortby"] = sortby
if paginate is not None:
payloads["paginate"] = paginate
r = requests.post(url, headers=headers, data=json.dumps(payloads))
return r.json()
東京周辺のシーンを検索してみます。この後に衛星画像をダウンロードするために、検索したシーンのデータセットID、シーンID、ダウンロードファイルIDを把握しておく必要があります。
AOIの座標指定時には、反時計周りで1つ目と5つ目の座標は同じ値を設定してください。
# プロパティ指定条件:観測バンド(OPS)=白黒、処理レベル=1B-a、解像度=30m
pprint.pprint(
scene_search_crossing(
intersects={
"type": "Polygon",
"coordinates": [
[
[139.7007411, 35.6670932],
[139.7432656, 35.6670932],
[139.7432656, 35.6939942],
[139.7007411, 35.6939942],
[139.7007411, 35.6670932],
]
],
},
query={
"tellus:bands": {"eq": "panchromatic"},
"processing:level": {"eq": "1B-a"},
"gsd": {"eq": 30},
},
sortby=[{"field": "properties.end_datetime", "direction": "desc"}],
paginate={"size": 10, "cursor": None},
)
)
検索結果として以下のようにシーン情報が出力されます。以下のシーンは国立競技場付近のデータにあたります。

続いて、検索したシーンのデータセットID、シーンIDを用いて、ダウンロードしたいファイルIDを検索します。
以下のようにファイル一覧情報取得API、個別ファイル情報取得API 、ダウンロードURL取得APIを定義します。
# ファイル一覧情報取得API
def get_files_list(dataset_id, data_id):
url = "https://www.tellusxdp.com/api/traveler/v1/datasets/{}/data/{}/files/".format(
dataset_id, data_id
)
headers = {"Authorization": "Bearer " + TOKEN, "content-type": "application/json"}
r = requests.get(url, headers=headers)
return r.json()
# ファイル情報取得API
def get_file_info(dataset_id, data_id, file_id):
url = "https://www.tellusxdp.com/api/traveler/v1/datasets/{}/data/{}/files/{}/".format(
dataset_id, data_id, file_id
)
headers = {"Authorization": "Bearer " + TOKEN, "content-type": "application/json"}
r = requests.get(url, headers=headers)
return r.json()
# ダウンロードURL取得API
def get_download_url(dataset_id, data_id, file_id):
url = "https://www.tellusxdp.com/api/traveler/v1/datasets/{}/data/{}/files/{}/download-url/".format(
dataset_id, data_id, file_id
)
headers = {"Authorization": "Bearer " + TOKEN, "Content-Type": "application/json"}
r = requests.post(url, headers=headers)
return r.json()
衛星画像の検索~ダウンロードまでの方法は別の記事に詳細がまとまっているので こちら をご覧ください。
先ほど定義したファイル一覧情報取得APIを使ってダウンロードするファイルのIDを確認します。今回は以下のファイル情報をダウンロードしたいと思います。
# ファイルをダウンロードしたいシーン情報を定義 dataset_id = "3ba0d35d-95c6-429d-af8b-f8d09ad318b3" data_id = "9972ccc1-0dec-4cf8-a951-02fcd2267906" print(get_files_list(dataset_id, data_id))
シーンに含まれるファイル一覧の出力結果が以下のようになります。

確認したファイルIDを用いて、ファイルのダウンロードを行います。ファイルはCOG形式のものを選択しています。
file_id = "1" # tifファイルを選択
# APIを実行
file_info = get_file_info(dataset_id, data_id, file_id)
download_url = get_download_url(dataset_id, data_id, file_id)
# 取得した情報から必要な情報を取り出す
url = download_url["download_url"]
file_name = file_info["name"]
size_bytes = file_info["size_bytes"]
print("ファイル名:" + file_name)
print("ファイルサイズ:" + str(size_bytes))
# 取得したファイルの内容を書き出す
response = requests.get(url)
with open(file_name, "wb") as f:
for chunk in response.iter_content(chunk_size=1024):
if chunk:
f.write(chunk)
f.flush()
# 取得した画像を表示する
io.imshow(file_name)
選択したファイルをダウンロードし表示した画像が以下になります。

画像を分割・結合する
表示範囲が広いためより細かく見るために、試しに国立競技場を映し出してみます。そのためには、一度画像を分解したうえで必要な範囲を複数結合する必要があります。
今回の場合、元の画像を縦に約40等分、横に約60等分しています。それを縦横それぞれに10個分結合し表示してみます。
# ファイルの画像サイズ img = io.imread(file_name) print(img.shape) img = transform.resize(img, (img.shape[0] * 2, img.shape[1] * 2, 3), anti_aliasing=True) row_split = 40 col_split = 60 # 画像を切り抜き row1_size = img.shape[0] // row_split col1_size = img.shape[1] // col_split img_tri = img[: (row1_size * row_split), : (col1_size * col_split), :] Ims = util.view_as_blocks(img_tri, (row1_size, col1_size, 3)) # 切り出した範囲を指定して画像を表示する io.imshow(img[row1_size * 20 : row1_size * 30, col1_size * 15 : col1_size * 25, :])
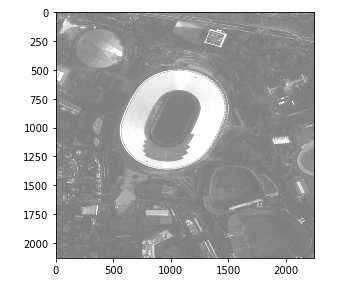
これで拡大して詳細を表示することができました。
SLATSは2019年の10月1日に運用を終了しています。短い期間ですが2019年の4月から10月までの東京周辺の様子を観測しています。
変化する東京の景色を観察するためには、衛星のシーンデータから撮影日時を条件に指定することで任意期間のデータを取得できます。
また、SLATSは東京だけでなく世界各地も観測していました。その中でもワイキキ、クウェート、ニース(フランス)の3 地点は定期的に観測が行われていました。
東京以外の景色の変化も、SLATSを利用して探してみてください。
今回使用したスクリプトです。
import json
import pprint
import requests
from skimage import io, transform, util
TOKEN = "ここに自分のトークンを貼り付ける"
# SLATSのシーン情報を取得
def scene_search_crossing(
datasets=None, intersects=None, query={}, sortby=None, paginate=None
):
url = "https://www.tellusxdp.com/api/traveler/v1/data-search/"
headers = {"Authorization": "Bearer " + TOKEN, "content-type": "application/json"}
payloads = {}
if isinstance(datasets, list):
payloads["datasets"] = datasets
if intersects is not None:
payloads["intersects"] = intersects
if query is not None:
payloads["query"] = query
if isinstance(sortby, list):
payloads["sortby"] = sortby
if paginate is not None:
payloads["paginate"] = paginate
r = requests.post(url, headers=headers, data=json.dumps(payloads))
return r.json()
# ファイル一覧情報取得API
def get_files_list(dataset_id, data_id):
url = "https://www.tellusxdp.com/api/traveler/v1/datasets/{}/data/{}/files/".format(
dataset_id, data_id
)
headers = {"Authorization": "Bearer " + TOKEN, "content-type": "application/json"}
r = requests.get(url, headers=headers)
return r.json()
# ファイル情報取得API
def get_file_info(dataset_id, data_id, file_id):
url = "https://www.tellusxdp.com/api/traveler/v1/datasets/{}/data/{}/files/{}/".format(
dataset_id, data_id, file_id
)
headers = {"Authorization": "Bearer " + TOKEN, "content-type": "application/json"}
r = requests.get(url, headers=headers)
return r.json()
# ダウンロードURL取得API
def get_download_url(dataset_id, data_id, file_id):
url = "https://www.tellusxdp.com/api/traveler/v1/datasets/{}/data/{}/files/{}/download-url/".format(
dataset_id, data_id, file_id
)
headers = {"Authorization": "Bearer " + TOKEN, "Content-Type": "application/json"}
r = requests.post(url, headers=headers)
return r.json()
# ダウンロードしたいファイル情報を定義
dataset_id = "3ba0d35d-95c6-429d-af8b-f8d09ad318b3"
data_id = "9972ccc1-0dec-4cf8-a951-02fcd2267906"
print(get_files_list(dataset_id, data_id))
file_id = "1" # tifファイルを選択
# APIを実行
file_info = get_file_info(dataset_id, data_id, file_id)
download_url = get_download_url(dataset_id, data_id, file_id)
# 取得した情報から必要な情報を取り出す
url = download_url["download_url"]
file_name = file_info["name"]
size_bytes = file_info["size_bytes"]
print("ファイル名:" + file_name)
print("ファイルサイズ:" + str(size_bytes))
# 取得したファイルの内容を書き出す
response = requests.get(url)
with open(file_name, "wb") as f:
for chunk in response.iter_content(chunk_size=1024):
if chunk:
f.write(chunk)
f.flush()
# 取得した画像を表示する
io.imshow(file_name)
# ファイルの画像サイズ
img = io.imread(file_name)
print(img.shape)
img = transform.resize(img, (img.shape[0] * 2, img.shape[1] * 2, 3), anti_aliasing=True)
row_split = 40
col_split = 60
# 画像を切り抜き
row1_size = img.shape[0] // row_split
col1_size = img.shape[1] // col_split
img_tri = img[: (row1_size * row_split), : (col1_size * col_split), :]
Ims = util.view_as_blocks(img_tri, (row1_size, col1_size, 3))
# 切り出した範囲を指定して画像を表示する
io.imshow(img[row1_size * 20 : row1_size * 30, col1_size * 15 : col1_size * 25, :])