Traveler APIを利用し、シーンを検索して衛星データをダウンロードする(前編)
はじめに
本記事ではJupyterLabを使ってTellus Satellite Data Traveler APIを利用し、衛星データをダウンロードする方法を前編、後編 に分けて紹介します。
前編ではシーンを検索し、シーン情報を取得します。後編ではシーンのファイル情報を取得し、データのダウンロードURLを生成します。今回はその前編です。
APIの詳細については こちら をご覧ください。
また、JupyterLabは事前に個別にセットアップしたものを使用しています。
APIトークンの発行
Traveler APIを使用するためにはAPIトークンが必要です。
APIトークンの発行方法 を参照して、APIトークンを生成してください。
本記事においてサンプルコードを貼り付ける際はTOKEN("TOKENXXXXXXXXXXXXXXXXXX"と表示されている部分)に生成したAPIトークンを貼り付けてください。
requests モジュールのインストール
APIの呼び出しにrequestsモジュールを使用するため、JupyterLab で利用される Python を python3.7 以降に設定します。また、requestsモジュールがインストールされていない方は以下のコマンドを実行しMacであればターミナル、Windowsであればコマンドプロンプトでインストールしてください。また、コマンドはJupyterLabの上で ! を先頭につけて実行することも可能です。
Anacondaを使用している方はバージョンによりますがデフォルトでrequestsがインストールされているケースが多いようです。
まずはpipがあることを確認します。
・ターミナルまたはコマンドプロンプト
pip -V
・JupyterLabで実行
!pip –V

pipがあることが確認出来たら以下のコマンドでrequestsモジュールを環境にインストールしてください。
pip install requests
インストールできたかは以下のコマンドで確認できます。
pip list
Anacondaを利用している方はcondaコマンドでrequestsモジュールのインストールができます。
conda install requests
pipはPython 3.4以降には標準で付属していますが、なければpipも適宜インストールしてください。
python get-pip.py
これで準備ができましたので、次からいよいよAPIの使い方を紹介します。
検索条件を指定してシーンを検索する
カタログ情報で絞り込む
JupyterLabを起動し以下のサンプルコードを貼り付けます。
関数呼び出し時の引数に検索条件を入力することで条件を付けて検索ができます。
ここでは、複数のデータセットを横断してシーン検索することができるAPI /data-search/ と、一種類のデータセットを指定してシーン検索を行うAPI /datasets/{dataset_id}/data-search/ を使用しています。
import json
import requests
TOKEN = "TOKENXXXXXXXXXXXXXXXXXX"
# API 呼び出しの共通設定
BASE_URL = "https://www.tellusxdp.com/api/traveler/v1"
REQUESTS_HEADERS = {
"Authorization": "Bearer " + TOKEN,
"Content-Type": "application/json",
}
def search_scene(datasets=None, intersects=None, query={}, sortby=None, paginate=None):
url = "{}/data-search/".format(BASE_URL)
payloads = {}
if isinstance(datasets, list):
if len(datasets) == 1:
url = "{}/datasets/{}/data-search/".format(BASE_URL, datasets[0])
else:
payloads["datasets"] = datasets
elif isinstance(datasets, str):
url = "{}/datasets/{}/data-search/".format(BASE_URL, datasets)
if intersects is not None:
payloads["intersects"] = intersects
if query is not None:
payloads["query"] = query
if isinstance(sortby, list):
payloads["sortby"] = sortby
if paginate is not None:
payloads["paginate"] = paginate
res = requests.post(url, headers=REQUESTS_HEADERS, data=json.dumps(payloads))
try:
res.raise_for_status()
except Exception as err:
raise SystemError("エラー:{}".format(err))
return res.json()
print(search_scene(
datasets=["1a41a4b1-4594-431f-95fb-82f9bdc35d6b", "b0e16dea-6544-4422-926f-ad3ec9a3fcbd"],
query={
"sar:observation_direction":{"eq":"left"},
"sat:orbit_state":{"eq":"descending"},
"view:off_nadir":{"gte":15,"lte":46.2},
"start_datetime": {"gte": "2022-01-12T00:00:00Z"},
"end_datetime": {"lte": "2022-01-20T23:59:59Z"}
},
sortby=[{"field": "properties.end_datetime", "direction": "desc"}],
paginate={"size":10,"cursor":None}
))
上記のコードでは以下の検索条件を設定し、ソートの条件と表示する件数の上限を指定しています。
検索条件
| 項目 | 内容 |
|---|---|
| データセット |
以下のいずれかと等しい。 【Tellus公式】PALSAR-2_L1.1 【Tellus公式】PALSAR-2_L2.1 |
| 観測方向(SAR) | left |
| 軌道方向 | descending |
| オフナディア角 | 15以上、46.2以下 |
| 撮影日 | 2022-01-12~2022-01-20 |
JupyterLabの画面イメージは以下のようになります。
枠で囲っている部分はご自身のAPIトークンと調べたい検索条件に置き換えてください。
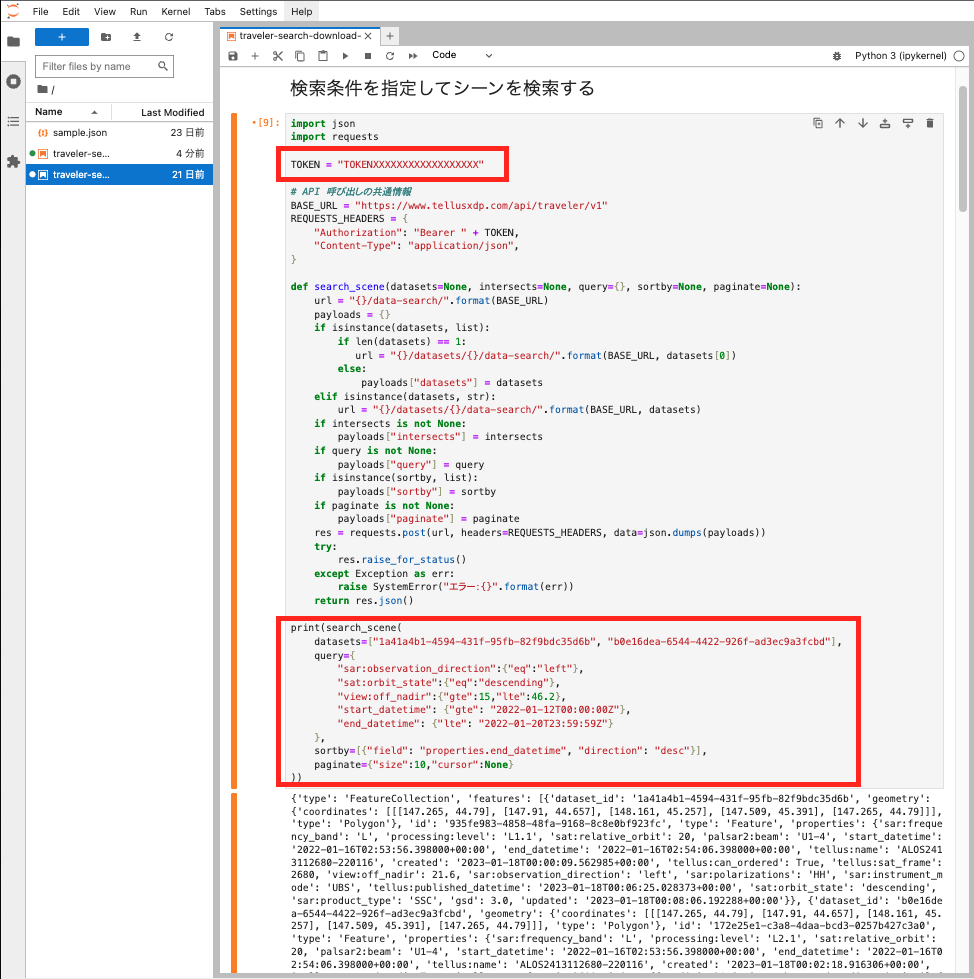
検索条件については シーン検索の条件に指定できるパラメータ または APIドキュメント のSchema情報等を参考にしてください。
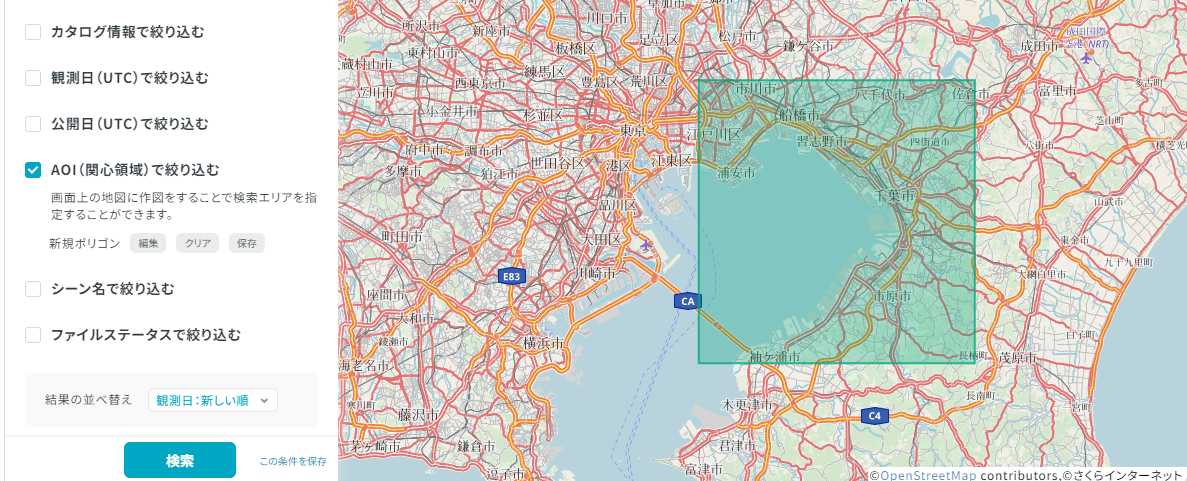
AOIで絞り込む
AOI(area of interest)を指定した検索方法も試してみてください。
シーンを検索する際に領域を条件に指定することもできます。
下の画像はTravelerの画面上でのAOI検索イメージ例です。
APIを使用して検索するコード例を以下に示します。
AOIはintersectsのcoordinatesに座標を指定します。この時、値は反時計回りに指定し、最初と最後の値は同じになるようにしてください。
import json
import requests
TOKEN = "TOKENXXXXXXXXXXXXXXXXXX"
# API 呼び出しの共通設定
BASE_URL = "https://www.tellusxdp.com/api/traveler/v1"
REQUESTS_HEADERS = {
"Authorization": "Bearer " + TOKEN,
"Content-Type": "application/json",
}
def search_scene(datasets=None, intersects=None, query={}, sortby=None, paginate=None):
url = "{}/data-search/".format(BASE_URL)
payloads = {}
if isinstance(datasets, list):
if len(datasets) == 1:
url = "{}/datasets/{}/data-search/".format(BASE_URL, datasets[0])
else:
payloads["datasets"] = datasets
elif isinstance(datasets, str):
url = "{}/datasets/{}/data-search/".format(BASE_URL, datasets)
if intersects is not None:
payloads["intersects"] = intersects
if query is not None:
payloads["query"] = query
if isinstance(sortby, list):
payloads["sortby"] = sortby
if paginate is not None:
payloads["paginate"] = paginate
res = requests.post(url, headers=REQUESTS_HEADERS, data=json.dumps(payloads))
try:
res.raise_for_status()
except Exception as err:
raise SystemError("エラー:{}".format(err))
return res.json()
print(search_scene(
intersects={
"type":"Polygon","coordinates":[
[
[-162.33,11.55],
[-149.32,11.55],
[-149.32,24.07],
[-162.33,24.07],
[-162.33,11.55]
]
]
},
query={
"start_datetime": {"gte": "2018-01-12T00:00:00Z"}
},
sortby=[
{"field": "properties.end_datetime", "direction": "desc"}
],
paginate={"size":10,"cursor":None}
))
JupyterLabの画面イメージは以下のようになります。
枠で囲っている部分はご自身のAPIトークンと調べたい検索条件に置き換えてください。
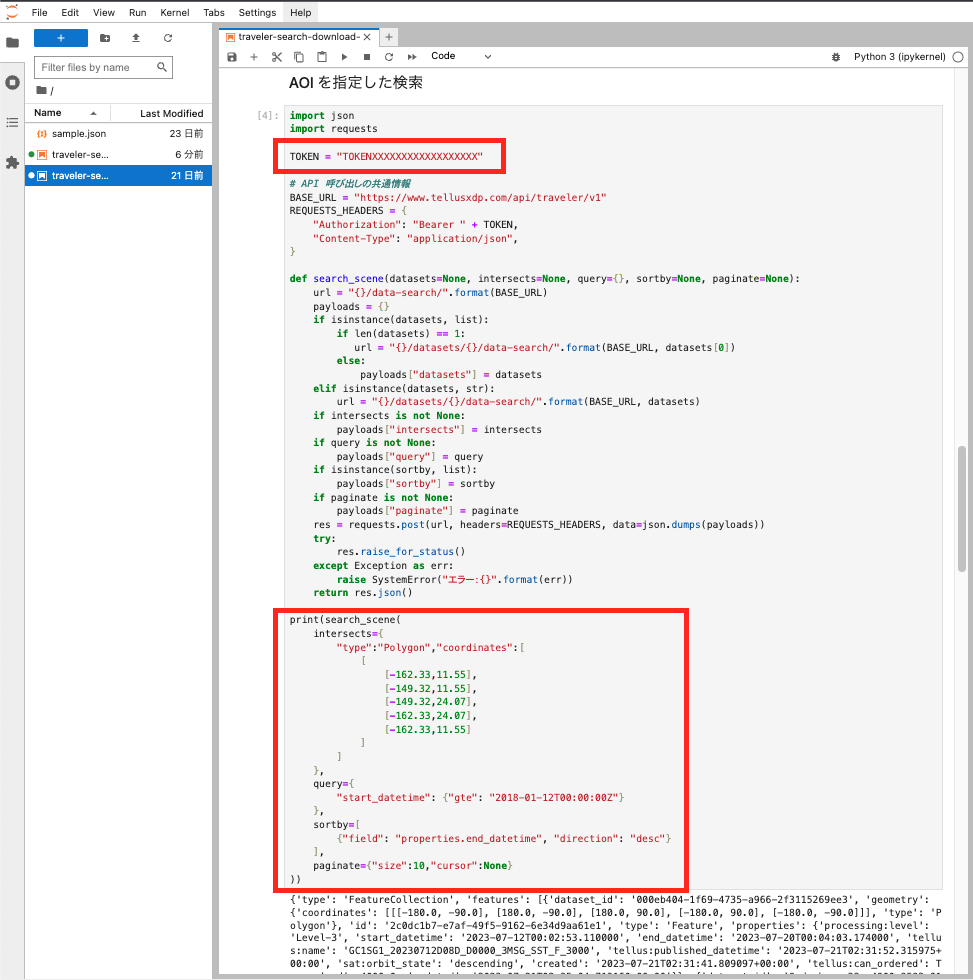
検索条件を手入力するのが難しい場合、Travelerの画面上で検索した条件を利用して検索することもできます。
まず、Travelerの画面上で任意の検索条件を指定してシーン検索を行います。
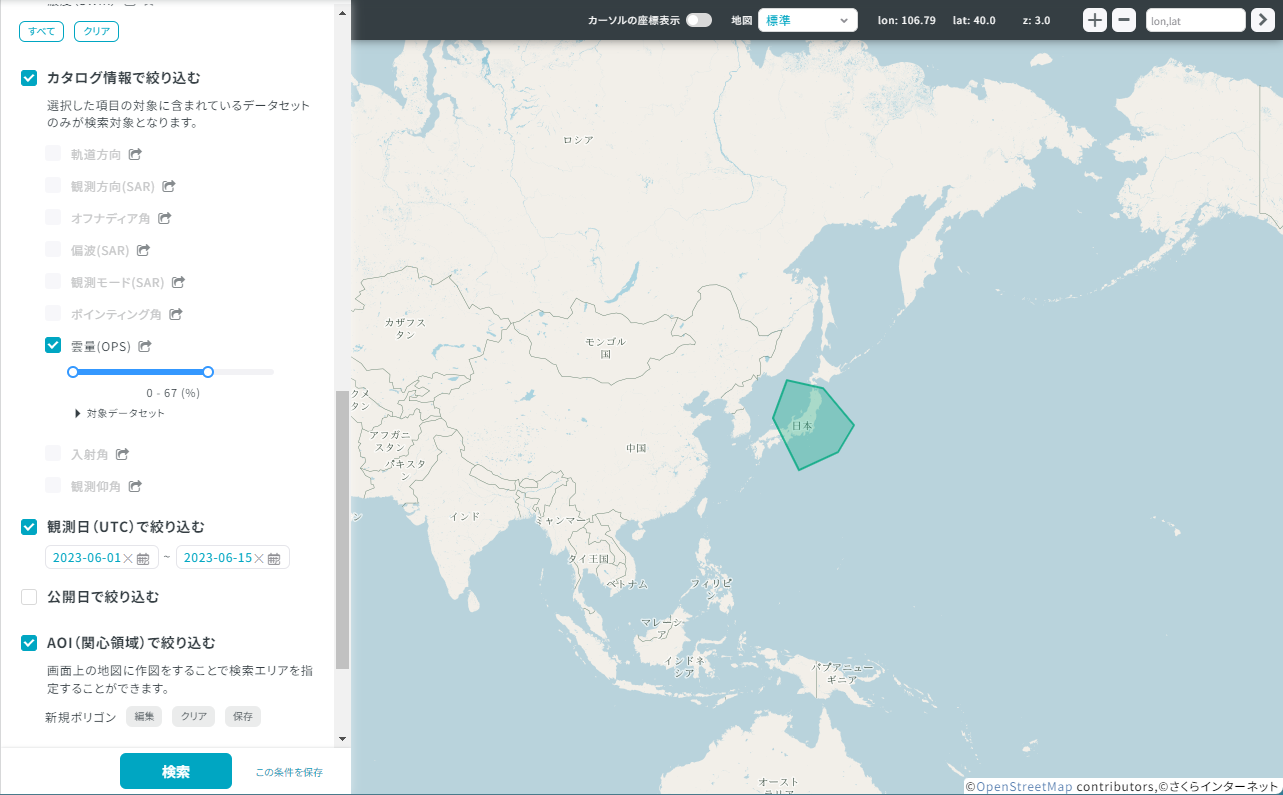
「この条件を保存」ボタンをクリックしたときに表示されるポップアップ内の「条件詳細(JSON)」をコピーします。
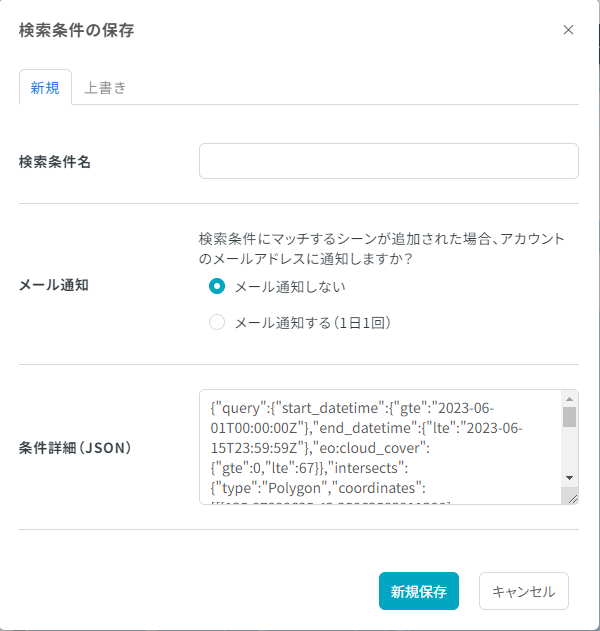
{任意のファイル名}.json としてファイルを作成し、条件をペーストして保存します。
例では、以下の内容を sample.json というファイル名で保存します。
{
"query": {
"start_datetime": { "gte": "2023-06-01T00:00:00Z" },
"end_datetime": { "lte": "2023-06-15T23:59:59Z" },
"eo:cloud_cover": { "gte": 0, "lte": 67 }
},
"intersects": {
"type": "Polygon",
"coordinates": [
[
[138.44970703125, 34.795474269863455],
[141.78131103515625, 34.795474269863455],
[141.78131103515625, 36.81285280928946],
[138.44970703125, 36.81285280928946],
[138.44970703125, 34.795474269863455]
]
]
},
"datasets": [
"182d2ec2-e296-4e18-9c1a-5f769416f23d",
"21d74302-bbc0-4f14-8192-3aad0986b197"
],
"sortby": [{ "field": "properties.end_datetime", "direction": "desc" }]
}
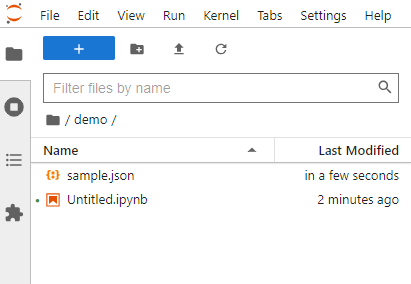
作成したjsonファイルをJupyterLabにアップロードします。
画面イメージではdemoというフォルダ内にアップロードしています。
以下の検索スクリプトをJupyterLabで実行します。
事前に、検索条件の json ファイルをスクリプトファイルと同じディレクトリに保存し、`%%JSON_FILE_NAME%%` を json ファイル名に書き換えます。
json に設定された検索条件でシーン検索が行われます。
import json
import requests
TOKEN = "TOKENXXXXXXXXXXXXXXXXXX"
# API 呼び出しの共通設定
BASE_URL = "https://www.tellusxdp.com/api/traveler/v1"
REQUESTS_HEADERS = {
"Authorization": "Bearer " + TOKEN,
"Content-Type": "application/json",
}
def search_scene_by_json(filename):
condition = json.load(open(filename))
url = "{}/data-search/".format(BASE_URL)
res = requests.post(url, headers=REQUESTS_HEADERS, json=condition)
try:
res.raise_for_status()
except Exception as err:
raise SystemError("エラー:{}".format(err))
return res.json()["features"]
# print(scene_search_by_json("sample.json"))
print(search_scene_by_json("%%JSON_FILE_NAME%%"))
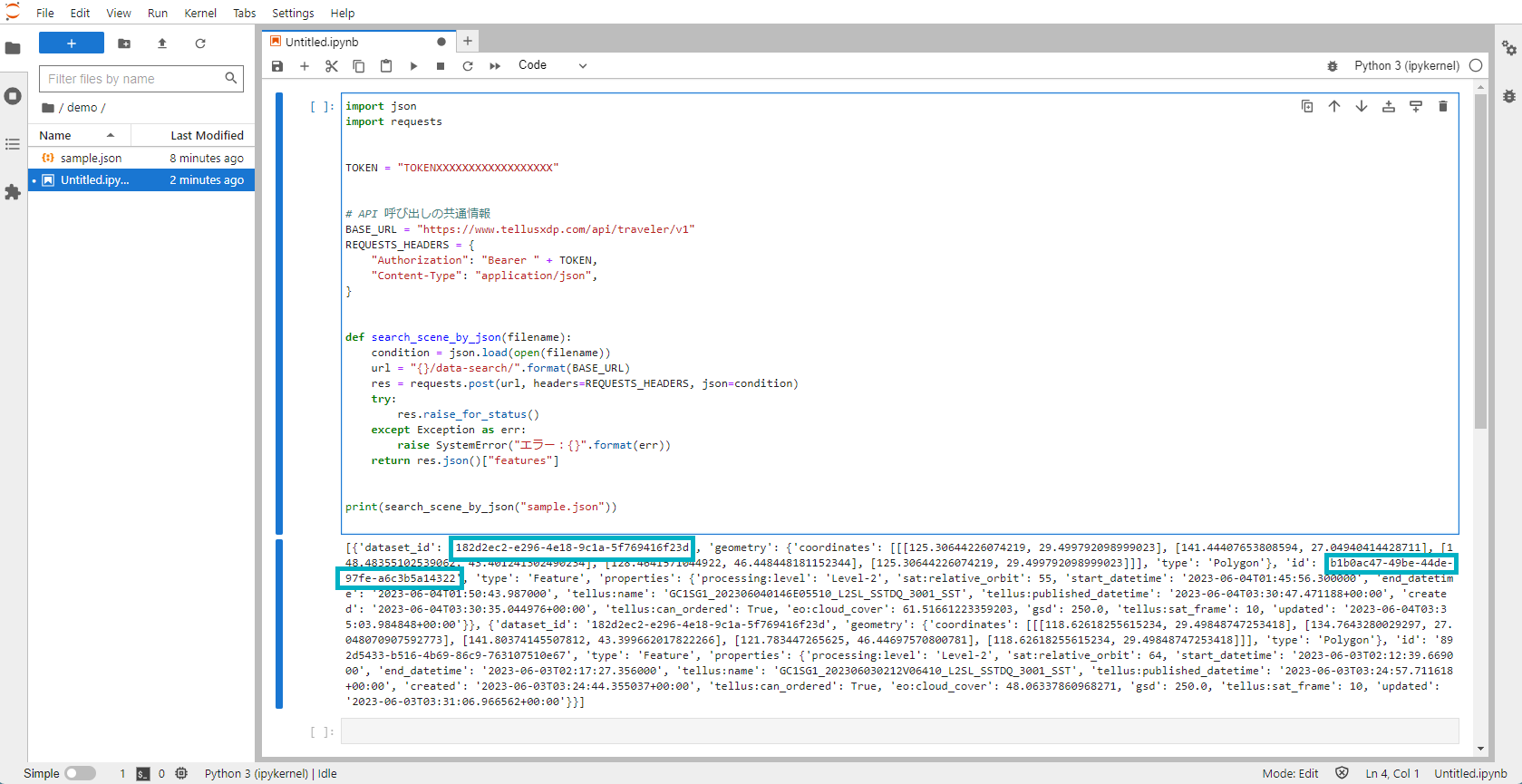
実行結果の青枠部分はこの後のAPI紹介にて使用するdataset_idとdata_idです。
検索結果を元にシーン情報を取得する
個別シーンの情報を取得するためにAPIの/datasets/{dataset_id}/data/{data_id}/を使用します。
JupyterLabを起動し以下のサンプルコードを貼り付けます。
先ほど検索した結果からdataset_idとdata_idをサンプルコード内の関数の引数に設定してください。
import requests
TOKEN = "TOKENXXXXXXXXXXXXXXXXXX"
# API 呼び出しの共通設定
BASE_URL = "https://www.tellusxdp.com/api/traveler/v1"
REQUESTS_HEADERS = {
"Authorization": "Bearer " + TOKEN,
"Content-Type": "application/json",
}
def get_scene_info(dataset_id , data_id):
url = "{}/datasets/{}/data/{}/".format(BASE_URL, dataset_id, data_id)
res = requests.get(url, headers=REQUESTS_HEADERS)
try:
res.raise_for_status()
except Exception as err:
raise SystemError("エラー:{}".format(err))
return res.json()
print(get_scene_info('ea71ef6e-9569-49fc-be16-ba98d876fb73','e432ad2b-d49c-4b50-892a-3487bebb0148'))
JupyterLabの画面イメージは以下のようになります。
枠で囲っている部分はご自身のAPIトークンと調べたいシーン情報に置き換えてください。
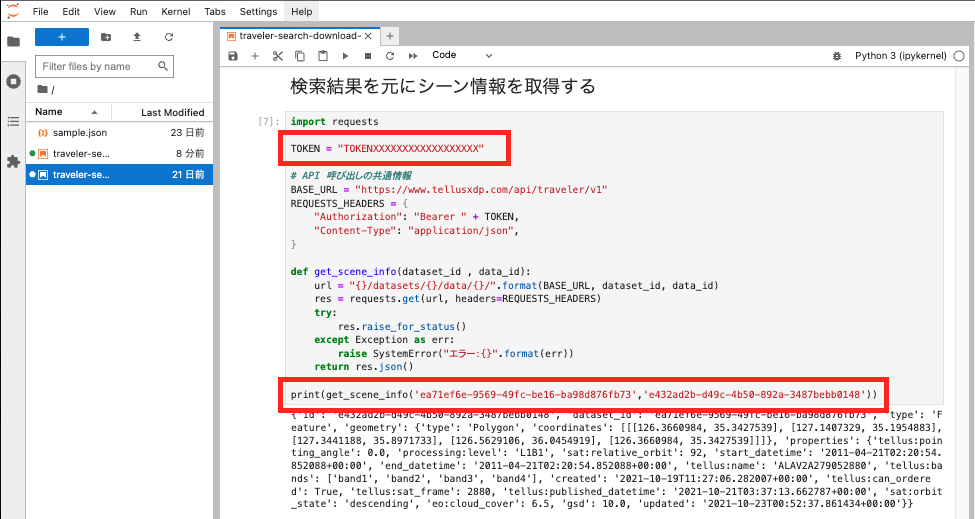
dataset_id (データセットID)はTravelerのデータセット詳細ページのIDで確認することができます。
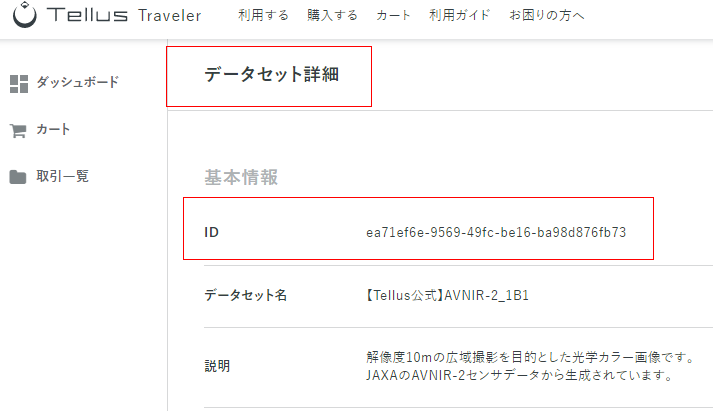
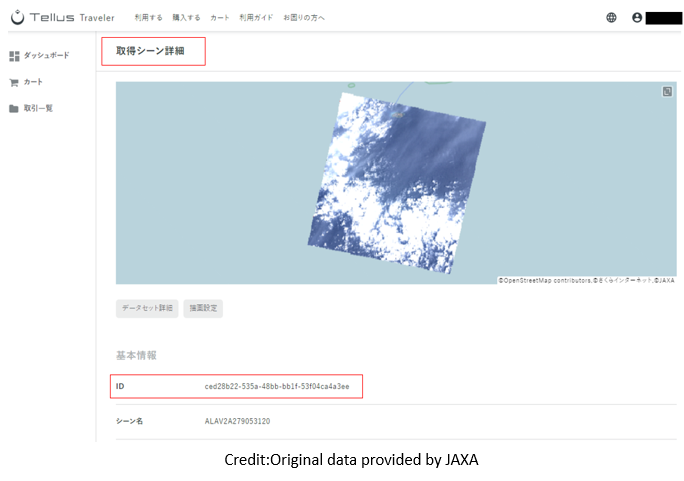
data_id(シーンID)はTravelerの取得シーン詳細ページのIDで確認することができます。
ここまででAPIトークンの発行、requests モジュールのインストール、検索条件を指定してシーンを検索する、検索結果を元にシーン情報を取得する方法を紹介してきました。
後編 ではシーンのファイル情報を取得する方法、ダウンロードURLの生成方法を紹介します。